
2022年3月25日,腾讯联合英伟达开发的TensorRT插件自动生成工具TPAT正式宣布开源。
TensorRT是当前应用最广的GPU推理框架,但由于支持的算子数量有限,用户面临手写插件以支持算子的痛点。TPAT能够支持开放神经网络交换 (ONNX) 格式所有的算子,端到端生成TensorRT插件,在解放人力成本的同时,性能对比手写毫不逊色。
Github地址:https://github.com/Tencent/TPAT
背景
TensorRT是当今最快的GPU推理引擎,可以让深度学习模型在GPU上实现低延迟、高吞吐量的部署,支持 Caffe,TensorFlow,Mxnet,Pytorch 等主流深度学习框架,由英伟达开发维护。业界几乎所有GPU推理业务都在使用TensorRT。
但是TensorRT也存在缺陷,即它的部署流程比较繁琐,因此算法工程师提供的模型需要交由系统工程师来部署上线,非常耗时耗力。在传统的TensorRT工作流里,手写插件往往是最耗时的一部分。

TensorRT手写算子插件难点
- TensorRT官方只支持很有限的常用算子(Conv/FC/BN/Relu…),对于不支持的算子,需要用户手写插件来实现;
- 插件的编写需要GPU和cuda知识,英伟达的工程师也通常需要1~2周时间来编写一个算子实现;模型中如果包含多个不支持算子,就需要更多时间来逐个编写和调试插件。
TPAT 概览
TPAT 实现了TensorRT插件的全自动生成,TensorRT的部署和上线能基本流程化不再需要人工参与。手写插件的步骤将由TPAT代替,TPAT全自动生成一个算子插件耗时仅需要30-60分钟的时间(该时间用于搜索算子的高性能CUDA Kernel),TensorRT会因此成为一个真正端到端的推理框架。

TPAT亮点
- 覆盖度:支持onnx/tensorflow/pyTorch所有的算子
- 全自动:端到端全自动生成用户指定的TensorRT Plugin
- 高性能:大部分算子上性能超越手写Plugin
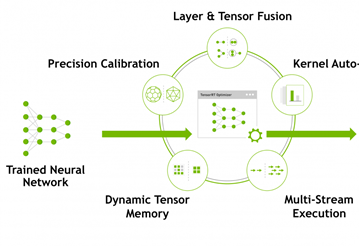
架构设计
TPAT部分算子性能数据
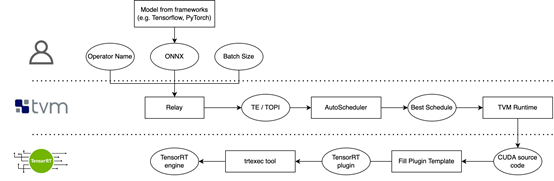
我们使用TPAT自动生成TensorRT-7.2不支持的算子,并且用TPAT优化TensorRT-7.2原生实现性能较差的算子;
对比手写Plugin

优化TensorRT原生算子

我们对内部业务模型里的部分算子进行了测试,TPAT的性能几乎全面超越CUDA工程师手写,并且端到端的设计能够大幅减少人力投入;对于TensorRT原生的算子实现,TPAT的表现也并不逊色,AutoTune的特点能够优化TensorRT里表现不那么好的原生算子实现。
TPAT开源
后续TPAT的开源计划:
- 对于算子的多精度进行支持,包括Float16,Int8.
- 利用TPAT进行子图的优化
- 对于动态形状的支持
附录:TPAT 使用案例
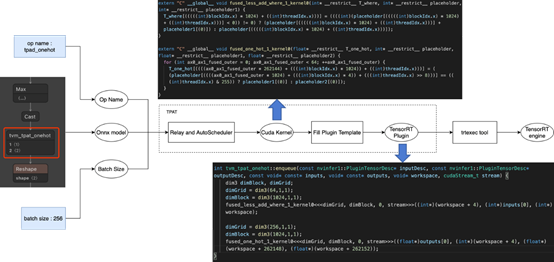
使用TPAT支持Onehot算子(TensorRT-7.2.2.3)
输入包括了onehot算子的ONNX_Model、Onehot算子的名字、batch_size TPAT借助TVM的Relay和AutoScheduler组件,生成高性能的CUDA Kernel; 经过模板填充后直接生成可用的onehot算子Plugin的动态链接库。

扫码关注w3ctech微信公众号
共收到0条回复