
前言
近期给实习生介绍一些基本概念,顺便梳理一下文章,方便之后可重复利用。 从事Web开发必须要了解从浏览器输入URL后到页面加载完之后的整个大概的流程,当然可以就某些点细化的研究下去,这一过程涉及到:HTTP/HTTPS协议、代理/反向代理、Web server、CGI、浏览器端的知识(HTML+Javascript+CSS) 只有把整个流程都梳理清楚,才有能力去讨论其他问题,例如如何去优化Web性能、如何利用工程化提高效率、在某些业务场景的技术方案取舍等。 本篇文章会以一个例子介绍计算机网络基本工作的过程,最终再详细介绍HTTPS是如何解决网络包加密问题。绘说明图找不到相关好的工具,所以文章引用了几张来自《图解TCP/IP》的图
快递
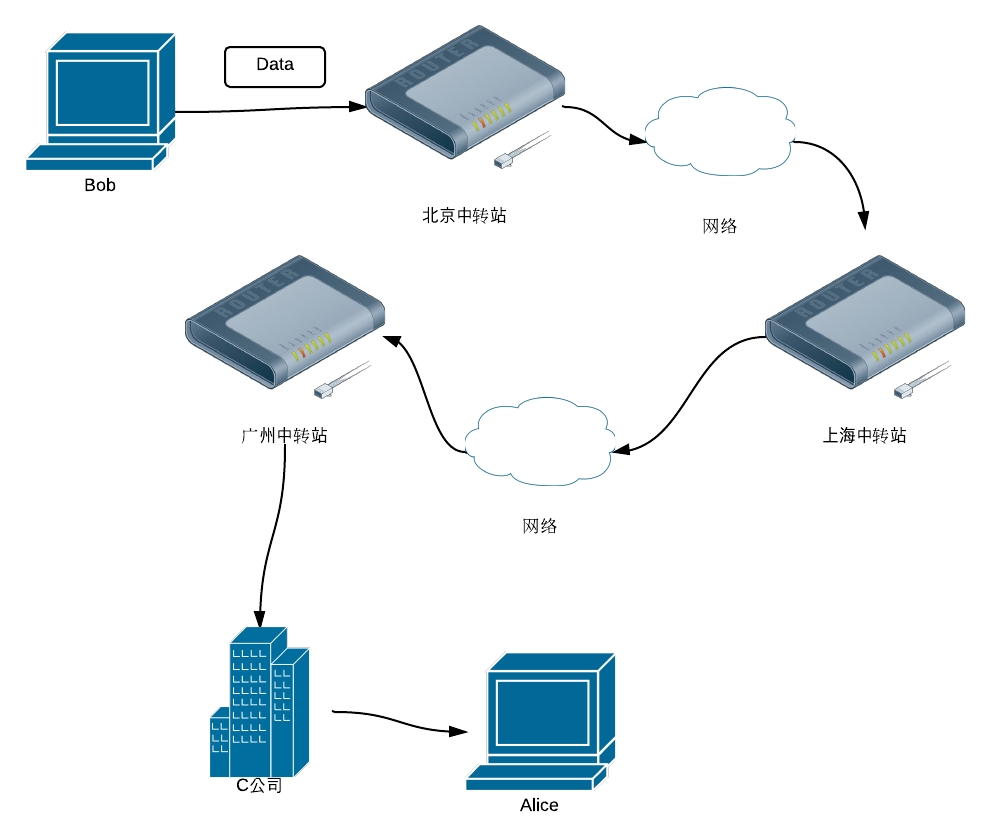
我们来看一个常常出现的场景: Alice在淘宝买了一件衣服,我们输入收货地址收货人付款后,卖家Bob帮我们把衣服打包放进纸箱里,贴上一个快递单:
寄件人:Bob 地址:北京市朝阳区朝阳路1号 收件人:Alice 地址:广东省广州市新港中路197号C公司 快递公司D派人去Bob家收到包裹,接着整理了公司的包裹,分批往个个城市送货。由于D公司没有直达广州的货运车,因此这些包裹先随着去上海的车到达上海的中转站之后,再把要发往广州的包裹搬到另一辆车发往广州中转站。 快递员Rapheal把快递送到C公司,快递中心的前台mm帮Alice签收后转交给了Alice。
计算机网络
以上的场景几乎就是计算机网络的场景了,我们做个类比(类比只到网络层):
朝阳路1号 == 北京某台计算机ip地址 新港中路197号 == 广州某台计算机的ip地址 快递单 == 包头 衣服 == 包体 快递公司的中转站 == 交换机/路由器 Bob == 北京某台计算机的进程B(端口) Alice == 广州C公司局域网里边的某台计算机的进程A(端口) C公司的快递中心 == C公司局域网的网关
上述类比并不严谨,这里仅仅简单解释一下网络里边发送/接收包的大概过程跟概念:
首先接入网络的计算机/路由器都要有一个ip地址,例如Alice的ip地址是120.0.0.2,Bob的ip地址是150.0.0.2。
 图片来自《图解TCP/IP》
图片来自《图解TCP/IP》Alice发送HTTP数据给Bob,实际上是Alice机器上的的进程a发送数据,Bob机器上的的进程b在接收数据,因为真正想要数据的进程才是最终应用层。
- 进程a发送数据是通过socket发出去,socket需要绑定一个端口,用于区分计算机内的不同进程。进程a使用的socket绑定了2048端口,进程b使用的socket绑定了4096端口。
所以Alice跟Bob通信实际上等价于:120.0.0.2的2048端口发送数据到150.0.0.2的4096端口 Alice的计算机发送数据:
进程a先把数据打包好,贴上单(HTTP协议头部):我来自Chrome浏览器; 我要Bob的index.html
- 再打包贴上单(TCP协议头部):发送端口2048,接收端口4096
- 继续包装贴上(IP协议头部):发送地址:120.0.0.2,接收地址:150.0.0.2。
这个包裹丢给快递公司(网络),接着就是快递公司负责送往目的地Bob的机器了。 路由器转发数据包:
快递公司中转站负责把当前的包裹传递到下一个快递中心,这也是路由器转发的原理
- 在北京的路由器先把包转到了离他近一点的天津,天津再转发到上海,上海再转发到广州,广州在转给海珠区的邮件中心,最后再到达目的地。
以下图片来自《图解TCP/IP》:

Bob的计算机接收数据包:
- 计算机收到来自150.0.0.2的包,解开后发现原来是送到端口4096去的,于是乎把包裹才开丢给了进程b(进程b使用的socket绑定了4096端口)
- 进程b拿到数据之后就可以做自己的操作了,如果他要回包给Alice,那就按照Alice打包的过程,生成一个包发送出去。
我们经常会听到计算机网络分成7层,可以这么理解:Bob把衣服装个箱子,箱子上贴个单说Alice收,接着再拿一个箱子装着,上边又贴了一个单写着腾讯公司收,最后再装一个箱子贴着广州新港中路197号收。这里的例子分成了三层,网络中运输的数据包也是这样的结构,IP包里边装着TCP包,TCP包里边装着HTTP包,每个协议层都有自己的包头(单)跟包体(箱子)。
以下图片来自《图解TCP/IP》:

协议
协议的目的就是让通信的双方知道当前这个数据包是怎么样一个组成格式,一般:包头就是双方约定好的一些信息,包体就是这次通信传输的数据。 Alice拿到快递之后从快递单(包头)就可以知道是Bob发给他的衣服,然后拆开之后就拿到衣服(包体),从而完成了此次通信。所以协议本身并没有那么复杂难解:协议 == 包头 + 包体。 协议繁琐的地方在于,计算机怎么识别每一层的包头,识别后做什么操作。例如路由器要识别出IP,然后决定当前数据包往那个地方转发;浏览器要识别出包头的Content-type,来决定当前这个包体是图片还是HTML。 刚刚说了包体其实就是数据本身,数据本身就没什么好理解的了,数据是什么,它就是什么,所以理解每一层的协议就在于理解其包头的含义。所以接下来我以HTTP头来介绍HTTP协议。
HTTP协议
刚刚说到其实协议就是让浏览器跟服务器互相知道他们要什么,因此浏览器发给服务器的包就要带着一些用户操作信息,服务器发给浏览器的包就要带着用户想要的数据信息。 当浏览器输入一个URL,相当于浏览器发起一个HTTP请求包出去,浏览器会把一些自身信息以及用户操作的信息写在包头上带到服务器,这样服务器才知道你在用什么浏览器想请求它的什么资源。
HTTP请求包的常见包头如下(紫色为说明文字):
- GET / HTTP/1.1 获取的路径以及HTTP版本
- Host: www.qq.com:8080 服务器主机名字&端口号
- Connection: keep-alive 用于长连
- User-Agent: Chrome/35.0.1916.153 浏览器基本信息
- Accept-Encoding: gzip,deflate,sdch 告诉服务器支持的编码
- Accept-Language: zh-CN,zh;q=0.8,en;q=0.6,nl;q=0.4,zh-TW;q=0.2 告诉服务器优先支持的语言
- Cookie: id=1;username=raphealguo; 解决HTTP无状态重要的Cookie,里边是key=value对 紧接着服务器收到HTTP请求,经过CGI处理之后回复一个HTTP响应包,服务器需要告诉你包里边是什么(Content-Type),包里边有多少东西(Content-Length),服务器版本是什么等等。
HTTP响应包常见的包头如下:
- HTTP/1.1 200 OK HTTP版本以及状态码
- Server: nginx/1.4.1 服务器版本
- Date: Mon, 30 Jun 2014 09:44:10 GMT 回包时间
- Content-Type: text/html; charset=UTF-8 包里边的类型
- Content-Length: 14534 包体的长度
- Connection: keep-alive 用于长连
- Cache-Control: no-cache, must-revalidate 用于缓存控制 具体的HTTP协议的细节推荐阅读《HTTP权威指南》。
HTTPS协议
北京的Bob发了一个快递到广州的Alice,途中经过了上海,上海快递中心出现了一个黑客H,他偷偷打开了Bob给Alice的快递,然后偷偷把里边的衣服剪烂,再按照原样包装好发往广州,可以看到对于这样简单包装的传输在中途是可以偷偷修改里边的东西。 HTTP的数据包是明文传输,也即是如果中途某个黑客嗅探到这个HTTP包,他可以偷偷修改里边包的内容,至于Bob跟Alice是互相不知道这个动作的,因此我们必须要有一个方案来防止这种不安全的篡改行为,有个方法就是加密!
非对称加密
Bob将衣服放到一个保险箱里边锁起来,他打了个电话告诉Alice保险箱开柜密码是1234,而黑客H不知道密码,所以他看不到保险箱里边的东西,Alice收到快递后用预先沟通好的密码就可以打开保险箱了。 这里保护的手段就是Bob对物品进行加密,同时给了告诉Alice解密的方法! 那如果现在要求Bob的密码只能通过快递传给Alice呢?如果Bob直接传密码给Alice,H如果嗅探到这个快递,那H也知道密码了,这就无法保护快递的安全性了。因此还需要有个方案,让Bob能够告诉Alice密码的同时,H又无法查看到Bob跟Alice通信的数据。 非对称加密在这个时候就发挥作用了,来看看怎么回事:Bob拥有两把钥匙,一把叫做公钥,一把叫做私钥。公钥是公开让全社会都知道,没关系,Bob告诉所有人,你们要传递数据给我的时候请先用这个密钥去加密一下你们的数据,加密后的数据只能通过Bob私自藏着的私钥才能解密。 回到刚刚例子,Bob先发给保险柜(Bob公钥)给Alice,接着Alice把自己的保险柜(Alice公钥)放到Bob的保险柜里边发还给Bob,接着Bob拿到Alice的回包后,用自己的私钥解开了外层保险柜,拿到了里边Alice保险柜。此时Alice跟Bob都有了各自的公钥,接着只要保证每次互相传递数据的时候,把数据放在对方的保险柜里边即可,这样无论如何,H都无法解开保险柜(因为只有各自的私钥才能解开各自的保险柜)。
HTTPS隧道
为了使得HTTP传输的安全性,HTTPS就诞生了,同刚刚Bob跟Alice通信一样,HTTPS会有如下的过程:
- 客户端先跟服务器做一次SSL握手,也就是刚刚Bob跟Alice交换公钥的过程。
- 此时客户端跟服务器都有了各自的公钥,这时他们中间相当于有了一条安全的HTTPS隧道。
- 客户端要发送请求时,采用服务器给的公钥对请求包进行加密,然后发出去。
- 服务器收到请求后,使用自己的私钥解开了这个请求包得到其内容。
- 服务器响应的时候,采用客户端给的公钥进行加密,然后发还给客户端。
- 客户端收到响应后,使用自己的私钥解开响应包得到其内容。
- 结束的时候,双方关闭SSL隧道,丢掉上次交换的公钥。
以下图片来自《图解TCP/IP》:

HTTPS安全?
那HTTPS是不是任何情况都安全的呢?从刚刚的例子中我们可以看到HTTPS其实是一个端到端的安全保障,HTTPS保障的是你这个数据包在传输的过程中无法被查看,但是这个数据包也是可以被黑客偷偷丢掉或者毁坏。来看看HTTPS在什么情况下是不安全的:
- 私钥被窃取,如果这个被爆了,那HTTPS肯定就不安全了
- HTTPS是无法保证端内安全,也即是如果你的电脑已经被病毒侵入,病毒可以监听到你开锁的时候,也可以知道你的私钥,那这份数据怎么样都保证不了安全性了。
- HTTPS下的页面引用了HTTP下的资源,例如HTTPS下的页面引用了HTTP下的Javascript文件,此时如果这个Javascript文件被篡改了,那通过这个JS文件就可以在执行的时候获取到整个网页内容,在这种情况下,某些浏览器会阻止你去加载这些非HTTP资源,有些则会提示错误或者给出警告信息。

扫码关注w3ctech微信公众号
-

原谅我眼里只看到了Alice和Bob,似乎又回到了网络安全的课堂
回复此楼 -

写的细腻,感觉把公钥和私钥描述成”开着的保险箱”和“关着的保险箱”会更好理解。
回复此楼
共收到2条回复